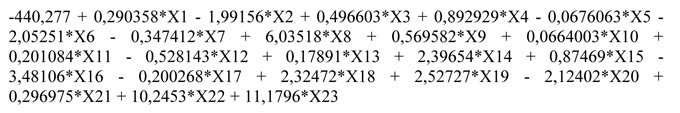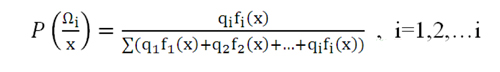En la publicación 'Descripción de Cepajes del Mundo', de la Organización Internacional de
la Viña y el Vino (O.I.V.) y en la actualización 'Lista alfabética de cepajes - Complemento
2007' se presentan las fichas ampelográficas de variedades de 'Vitis Vinífera' por país de
origen. Estas fichas poseen 89 códigos por varietal, más 45 códigos medidos solo en algunos
varietales. Es decir, la cantidad de caracteres a medir es muy grande y compleja. Este trabajo
muestra cómo se desarrolló un software de identificación ampelográfica por medio de
mediciones sobre imágenes digitales y utilizando análisis discriminante para la clasificación
de muestras. Se logró obtener un porcentaje de aciertos de un 80,77% cuando se desconoce el
color de la baya sobre un total de 20 varietales, y un 94,12% y 92,78% para varietales blancas
o rosadas y tintas, respectivamente. La seguridad en la identificación se mejora al analizar
otras hojas de la misma planta.
Introducción
La biometría es el estudio de métodos automáticos de identificación de humanos a partir de la medición de ciertos rasgos propios de cada persona. Aplicando este concepto a hojas de vitis podría lograrse un reconocimiento de las mismas al medir sus características. Existe una gran cantidad de parámetros, características o variables que se pueden observar al momento de una identificación ampelográfica. En ocasiones el valor de estos parámetros es difícil de reconocer, a su vez, muchos de ellos solo pueden ser observados en ciertas épocas del año.
El objetivo de este trabajo fue desarrollar un software que se llamó 'Identificador de vid v.1.1' y que servirá para el reconocimiento de varietales, partiendo de la hipótesis de que existen ciertos parámetros en las hojas de vid que son estadísticamente particulares de cada varietal.
Materiales y métodos
El software se desarrollo sobre la plataforma de MatLAB versión 7.9.0.529 (R2009b), generando un GUI (interface grafica de usuario), para una mayor comodidad de los usuarios al momento de realizar las mediciones. La programación en lenguaje M de MatLAB es relativamente sencilla, en MatLAB las imágenes son tratadas como matrices lo que permite un manejo matemático de ellas, donde cada píxel de la imagen es un elemento de la matriz. Como obviamente las hojas de cada varietal son diferentes, incluso el polimorfismo en cualquier planta de vid puede ser muy elevado, se generó inicialmente una base de datos de cada varietal para ser tratada estadísticamente.
Generación de la base de datos
Se recolectaron imágenes digitales de viñedos y algunas de bibliografía para construir la base de datos. Los criterios al tomar y seleccionar las imágenes fueron:
Imagen nítida. Colocando una hoja de papel blanca detrás de las hojas de vid se logró buen contraste.
Largo mínimo recomendable del limbo = 280 píxeles (N3).
Al menos una mitad de la hoja bien desplegadas.
Imágenes sobre hojas adultas, enteras, sanas, preferentemente del tercio medio del pámpano.
Respetar la proporción normal de imagen de 1,33 pixeles de ancho/ píxeles de largo.
La base de datos fue creada con mediciones de 20 variedades de vitis muy difundidas en la Argentina. Esta se obtuvo con el mismo software desarrollado, ya el mismo permite generar una hoja de cálculo con la matriz de los datos medidos (Fig.4).
Primeramente las imágenes son rotadas, ajustadas en escala y centradas para luego poder realizar las mediciones de distancias y ángulos de manera estandarizada, se llevan a un largo de nervio que va desde el seno peciolar hasta el ápice igual a 280 pixeles (N3). Luego se midieron los parámetros que se encuentran enumerados en los Cuadros 1 y 2. Ver referencias en Fig.1. El usuario solo debe marcar los puntos que se van indicando y el software realiza las mediciones en pixeles y ángulos.
En total son 19 variables cuantitativas para lo cual se deben marcar 9 puntos e indicar la cantidad de dientes, todas estas mediciones se realizan solo sobre la mitad del limbo. Por otra parte se indican 4 datos más correspondientes a variables cualitativas. La cantidad total de mitades de hojas medidas para la base de datos fue de 182.
Fig.1: Referencias de variables cuantitativas.
Cuadro 1: Variables cuantitativas.
Cuadro 2: Variables cualitativas.
Cuando no existe un seno lateral, por ejemplo el S2, el programa considera S2, E4 y E5 con un valor de largo y ángulo igual al de un punto intermedio entre N2 y N3. Las muestras de la base de datos fueron codificadas según:
'Identificador de vid' captura el nombre del archivo de imagen para luego utilizarlo para identificar la fila de variables de la muestra en la base de datos. Las abreviaturas utilizadas para la codificación de muestras en la base de datos se muestran en el Cuadro 3.
Cuadro 3: Abreviatura de varietales.
Funciones de clasificación
Los datos de las 23 variables medidas en las 182 mitades de hojas que se encontraban en la hoja de cálculo generada por el software 'Identificador de vid', se volcaron en el software Statgraphics Centurion XV, versión 15.2.06, para generar las funciones de clasificación de todas las hojas por un lado, por otro solo los datos de las hojas que pertenecen a varietales blancas y rosadas, y por otro los datos de las que pertenecen solo a tintas. Estas funciones se presentan en Statgraphics como tablas formadas por los 'coeficientes de las funciones de clasificación de las distintas variedades', es decir, cada varietal (agrupación) posee una función de clasificación, por ejemplo la del\1CV\2 Criolla Grande, que maximiza las diferencias con las otras agrupaciones es:
Xi es cada uno de los parámetros medidos de las hojas. Para evaluar una muestra desconocida, se debe reemplazar los valores medidos en cada una de las ecuaciones, los resultados serán puntajes, siendo el más alto de ellos el que corresponde a la agrupación donde se ubica la muestra, es decir que la muestra tiene mayor probabilidad de corresponder a esa agrupación.
Clasificación de nuevas observaciones con MatLAB
En MatLAB la función 'classify' nos permite obtener tanto la clasificación utilizando análisis discriminante, como el error y la probabilidad posterior de una muestra a partir de una matriz de entrenamiento. Esta es la matriz 'base de datos'.
Clasificiación
Es el varietal reconocido en la muestra.
Error
Es una estimación de la tasa de errores por mala clasificación que se basa en los datos de entrenamiento. Devuelve la tasa de error aparente, es decir, el porcentaje de observaciones que en la base de datos están mal clasificadas, ponderado por las probabilidades a priori para los grupos.
Probabilidad posterior
Es una matriz que contiene estimaciones de las probabilidades a posteriori. Para el cálculo de la probabilidad posterior se utiliza la 'regla de Bayes': la probabilidad de que x pertenezca a un grupo es igual a la probabilidad previa por la probabilidad de la agrupación si se cumple con la condición de x, esto último es la función de densidad fi(x):
Siendo Ωi una agrupación i, q son las probabilidades previas, P (Ωi/x) es la probabilidad a posteriori de que x pertenezca a la población Ωi. fi (x) son las funciones de densidad que describen las poblaciones.
La regla de clasificación es: P (Ω1/x) > P (Ω1/x), asignamos x a Ω1 en caso contrario asignamos x a Ω2.
Tanto la clasificación, como el error y la probabilidad posterior son los resultados del análisis que se presentan en la pantalla del 'Identificador de vid'.
Resultados y discusión
Con los 182 datos se logró un porcentaje de casos correctamente clasificados de 80,77%. Al indicar el color de la baya se mejoró considerablemente la cantidad de aciertos. En las variedades blancas y rosadas el porcentaje de casos correctamente clasificados fue del 94,12%. En las tintas el porcentaje de casos correctamente clasificados fue de 92,78%. En las Fig. 2 y 3 se muestran las gráficas de las funciones discriminantes para variedades blancas y rosadas y para tintas, respectivamente.
Fig.2: Funciones discriminantes para variedades blancas y rosadas.
Fig.3: Funciones discriminantes para variedades tintas.
Conclusiones
Se logró el objetivo perseguido al desarrollar el software de identificación ampelográfica mediante una nueva metodología, encontrándose las siguientes fortalezas y debilidades:
Fortalezas de la metodología analítica
Las hojas se encuentran disponibles en la planta en un gran período del año.
Parámetros claros que pueden medirse incluso desde imágenes tomadas de la cara inferior de las hojas.
Se logra una identificación solo con una imagen digital sin tener que recurrir al viñedo.
Necesita una resolución de imagen pequeña (640 x 480 pixeles), siempre y cuando la hoja ocupe más del 60% de la misma.
Posibilidad de compilación del software para funcionar sin necesidad de contar con MatLAB.
Con los resultados obtenidos se puede comenzar a desarrollar una nueva edición del software que permita la lectura de los puntos N1, N2, S1, S2, E1 a E5 en forma automática, utilizando funciones de rotación y binarización, gracias a que solo se trabaja con puntos ubicados en la línea de contorno de la hoja de vitis.
Fig.4: Software 'Identificador de vid'. Pantalla de inicio.
Debilidades de la metodología analítica
Existe el error de que se identifique la hoja con una variedad que no es la correcta. Lo aconsejable para disminuir este error es medir varias hojas de una misma planta.
Se ha ingresado en la base de datos solo 20 variedades de vid.
Al momento solo se ha creado un base de datos con mediciones de 182 hojas, se mejorará la clasificación al ingresar más datos.
El agregado de otras variedades de vitis requerirá de mayores parámetros ampelográficos. En pruebas realizadas se observó que se mejora considerablemente la clasificación cuando el análisis discriminante incluye 7 varietales como máximo, lo que indica que para mayor cantidad de varietales sería conveniente agregar otra variable como por ejemplo 'forma de la baya', la cual puede evaluarse también a través de una imagen digital. Otra posibilidad es trabajar con una imagen del racimo.
Agradecimientos
Agradecimientos al Vivero Mercier, Facultad de Ciencias Agrarias y Universidad Nacional de Cuyo por permitir la toma de imágenes de sus vides, y a los ingenieros agrónomos Carla Aruani y Alejandro Marianetti por la información brindada.
Referencias bibliográficas
Grupo de Extertos de la O.I.V. 1993. Descripción de variedades de vid del mundo. Edición Julio 1993. Paris. Oficina Internacional de la Viña y el Vino.
Grupo de Extertos de la O.I.V. 2001 Lista de descriptores OIV para variedades de vid y especies de vitis. 2da Edición. Paris. Oficina Internacional de la Viña y el Vino.
Kuonqui Bravo G. Sang H. Extraccion de caracteristicas y comparacion de una Huella digital.
Barragán Guerrero D. 2008. Manual de interfaz gráfica de usuario en MatLAB parte 1. Matpic.com.
Cuevas Jimenez. Zaldivar Navarro D. Visión por Computador utilizando MatLAB y el Toolbox de Procesamiento Digital de Imágenes.
Cuadras C. 2008. Nuevos métodos de análisis multivariante. CMC Editions Barcelona España.
Responsable: Interempresas Media, S.L.U. Finalidades: Suscripción a nuestra(s) newsletter(s). Gestión de cuenta de usuario. Envío de emails relacionados con la misma o relativos a intereses similares o asociados.Conservación: mientras dure la relación con Ud., o mientras sea necesario para llevar a cabo las finalidades especificadasCesión: Los datos pueden cederse a otras empresas del grupo por motivos de gestión interna.Derechos: Acceso, rectificación, oposición, supresión, portabilidad, limitación del tratatamiento y decisiones automatizadas: contacte con nuestro DPD. Si considera que el tratamiento no se ajusta a la normativa vigente, puede presentar reclamación ante la AEPD. Más información: Política de Protección de Datos
Empatía con los comensales, cuidar a los proveedores, tener ganas de mantenerse actualizado y de seguir aprendiendo y ser objetivo son las aptitudes más importantes para ser sumiller
El vino espumoso merece ser reconocido y potenciado por lo que es: un vino serio, con trayectoria y que recoge la historia de muchas familias de este o de otros países