
Paradigma desvela el mapa del quién es quién en Big Data
Comunicaciones Hoy07/09/2016
 El 70% de las empresas confía en Big Data para la toma de decisiones, ya sea acortando los tiempos, creando modelos predictivos o incluso con la automatización de la toma de decisiones. Sin embargo, la mayoría de las empresas desconocen los nombres y las posibilidades que se esconden detrás de tecnologías como Spark, Kafka, Cassandra, Flume, Elastic, MongoDB
El 70% de las empresas confía en Big Data para la toma de decisiones, ya sea acortando los tiempos, creando modelos predictivos o incluso con la automatización de la toma de decisiones. Sin embargo, la mayoría de las empresas desconocen los nombres y las posibilidades que se esconden detrás de tecnologías como Spark, Kafka, Cassandra, Flume, Elastic, MongoDB
Y es que ante el vertiginoso avance y continua mejora de las tecnologías, la que hoy es una referencia indiscutible para el ecosistema de Big Data mañana puede quedar obsoleta ante la aparición de una nueva tecnología que revoluciona el mercado. Como ha sucedido con Spark, que ha relevado completamente a una de las tecnologías que se venía utilizando habitualmente como Hadoop, o la irrupción de Kafka que se ha convertido en el bus de mensajería del siglo XXI por su capacidad distribuida y escalabilidad.
Big Data está en la base de todas las grandes tendencias de hoy en día, desde las redes sociales al mundo móvil, pasando por el cloud y el gaming. Para ayudar a las empresas a conocer mejor quién es quién en el ecosistema de Big Data, Paradigma (www.paradigmadigital.com), multinacional española especializada en la transformación digital de las empresas, ha publicado una práctica infografía con la veintena de tecnologías más relevantes a día de hoy, en la que destacan Spark y Kafka, y sus diferentes campos de aplicación.
Los datos son la gasolina de cualquier sistema Big Data y, a veces, nos encontramos con ideas que, siendo buenas desde el punto de vista de negocio y estando bien plasmadas, son irrealizables en un plazo y coste razonables por no disponerse de medios para la adquisición de los datos necesarios para acometerlos, apunta José Ruiz Cristina, director de Big Data de Paradigma.
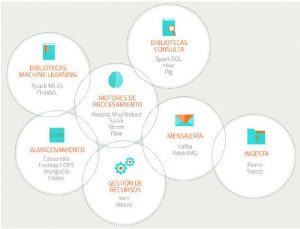
Para ello, la infografía desvela las siete grandes áreas de clasificación de las tecnologías Big Data:
#1. Ingesta: para la recolección de los datos desde su origen, tanto en bases de datos tradicionales o en flujos continuos a través de la red. Aquí destacan tecnologías como Flume o Sqoop.
#2. Almacenamiento: para guardar y gestionar grandes volúmenes de datos, como pueden ser las bases de datos NoSQL. Nos encontramos con Cassandra, Hadoop HDFS, MongDB o Elastic.
#3. Gestión de recursos: para la planificación y asignación de los recursos del clúster donde se lleva a cabo el procesamiento. Existen tecnologías como Yarn o Mesos.
#4. Motores de procesamiento: que son el verdadero corazón del Big Data. Son motores capaces de realizar el cómputo de manera distribuida, para repartir el trabajo entre varios nodos de computación y efectuar operaciones costosas en poco tiempo. Destaca, sobre todo Spark, que no sólo soporta el paradigma Map/Reduce sino un conjunto mucho mayor de transformaciones que pueden ser ejecutadas en paralelo y que lo hace hasta 100 veces más rápido que Hadoop MapReduce, otra de las tecnologías conocidas junto a Storm o Flink.
#5. Mensajería: para el intercambio de datos entre los diferentes componentes de manera eficiente. Nos encontramos con RabbitMQ y, sobre todo, con Kafka el nuevo bus de mensajería del siglo XXI tanto por su capacidad distribuida de alto rendimiento -al estar diseñado para manejar cientos de MB de mensajes por segundo, generados y consumidos por miles de clientes y ordenados en topics- como por su escalabilidad -al poderse ejecutar a lo largo de un cluster de nodos-.
#6. Bibliotecas de consulta: que son bibliotecas orientadas a simplificar el acceso a los datos y que se basan en los motores de procesamiento para formular las consultas de manera eficiente. Podemos citar aquí a Hive, Pig o Spark SQL.
#7. Bibliotecas machine learning: son algoritmos para clasificar, predecir o perfilar. Se basan en motores de procesamiento para ejecutar cálculos complejos muy rápido. Destacan Spark MLlib o FlinkML.
Conscientes de la complejidad del ecosistema de Big Data y la velocidad a la que evolucionan las tecnologías, Paradigma recomienda como primer paso un diagnóstico rápido de los datos de los que dispone o puede disponer fácilmente, la organización, para, a partir de esa visión, identificar un quick win realizable a corto plazo que aporte beneficios claros en poco tiempo y con una inversión razonable. Crecer a partir de ahí enriqueciendo las vías de adquisición de datos y mejorando la inteligencia sobre ellos, será mucho más fácil, de tal modo la organización se irá orientado poco a poco y de forma ordenada hacia el paradigma Data Centric: el apoyo de todos los procesos de negocio en inteligencia Big Data.


")
")











