Redes neuronales artificiales (RNA). Una herramienta predictiva en corrosión y recubrimientos.
Las redes neuronales artificiales (RNA) han transformado el análisis de datos en sectores industriales, optimizando procesos y mejorando la capacidad predictiva en múltiples aplicaciones. En el ámbito de los recubrimientos, su implementación permite anticipar la resistencia a la corrosión con alta precisión. En este artículo, José Javier Gracenea presenta un modelo basado en RNA para evaluar el comportamiento de recubrimientos anodizados sobre aleaciones de aluminio 2024 T3. A partir de datos electroquímicos obtenidos mediante ensayos ACET y resistencia a la polarización, el modelo alcanza una precisión del 96% en la predicción de la resistencia a la niebla salina. La metodología empleada, que incluye el ajuste de hiperparámetros clave, demuestra el potencial de la inteligencia artificial para optimizar la caracterización de recubrimientos. Esta investigación abre nuevas posibilidades para el control de calidad en la industria, facilitando el desarrollo de soluciones más eficientes y sostenibles.


Ambos tipos de neuronas están organizados en capas: las biológicas dentro de regiones especializadas del cerebro y las artificiales en redes neuronales con capas de entrada, ocultas y de salida. Mientras que las neuronas biológicas trabajan con señales bioquímicas y eléctricas, las artificiales procesan datos como imágenes, texto y sonido. Aunque las redes neuronales artificiales imitan algunos aspectos del cerebro, todavía están lejos de igualar la versatilidad y la complejidad del sistema nervioso humano.
McCulloch y Pitts (1943) propusieron un modelo matemático de neurona artificial, estableciendo las bases de las redes neuronales [1]. En 1958, Rosenblatt desarrolló el perceptrón, una red capaz de aprender ajustando sus pesos según los errores [2]. Sin embargo, Minsky y Papert (1969) demostraron que solo resolvía problemas lineales, frenando su avance por una década [3]. El desarrollo del algoritmo de retropropagación (1986) permitió entrenar redes profundas, impulsando los perceptrones multicapa (MLP) [4]. Con mayor capacidad computacional y datos, surgieron arquitecturas avanzadas como las redes neuronales recurrentes (RNN) y convolucionales (CNN). Desde 2012, con AlexNet en ImageNet [5], el aprendizaje profundo (deep learning, DP) ha revolucionado áreas como la visión artificial, el lenguaje natural y la robótica, consolidándose como una tecnología clave del siglo XXI.
Las redes neuronales artificiales imitan el aprendizaje del cerebro humano mediante neuronas artificiales interconectadas. Estas procesan datos numéricos, aplican pesos ajustables (resultado de salida=w*dato de entrada+ sesgo) y funciones de activación para generar una salida que, si no alcanza un valor umbral, no se traslada a la siguiente capa y, secuencialmente, a la capa de salida. La red se organiza en tres capas: entrada (datos), ocultas (procesamiento) y salida (resultado). El aprendizaje ocurre ajustando los pesos mediante una propagación hacia delante (feedforward) y una posterior retropropagación (backpropagation) del error, optimizando predicciones con cada iteración. Así, mejoran en tareas como la predicción de valores de parámetros, reconocimiento de imágenes, diagnóstico médico y traducción automática.
El entrenamiento se realiza mediante aprendizaje supervisado utilizando un conjunto de datos (dataset) etiquetados, es decir, datos que incluyen tanto las características de entrada como las de salida para que el modelo aprenda. El conjunto de datos se divide en conjunto de entrenamiento, que suele representar entre el 60% y el 80% del total, se usa para ajustar los parámetros del modelo; el conjunto de validación, que abarca entre el 10% y el 20%, se emplea para evaluar el rendimiento y ajustar hiperparámetros, evitando el sobreajuste. Por último, el conjunto de prueba, que representa aproximadamente el 10% restante, se reserva para evaluar el modelo final de manera imparcial.

La función de pérdida (loss function) es una medida que evalúa el desempeño de una red neuronal. Esta función cuantifica la discrepancia entre las predicciones del modelo y los valores reales del conjunto de datos. El objetivo del entrenamiento es minimizar esta función. Cuanto mayor sea esta diferencia, mayor será el valor de la función de pérdida. Durante el proceso de entrenamiento, se utilizan algoritmos de optimización (como el descenso de gradiente) para ajustar los parámetros del modelo (pesos y sesgo) con el fin de minimizar el valor de la función de pérdida. Este proceso se realiza iterativamente.


La validación en el aprendizaje automático permite detectar problemas como el sobreaprendizaje y ajustar hiperparámetros para mejorar el desempeño del modelo en datos nuevos.
Existen diferentes técnicas de validación, como la validación cruzada (cross-validation), donde los datos se dividen en múltiples subconjuntos y el modelo se entrena y evalúa varias veces con diferentes particiones del conjunto total de datos. Una validación efectiva permite ajustar los parámetros del modelo sin utilizar el conjunto de prueba, garantizando que las mejoras reflejen una mayor capacidad predictiva y no solo un ajuste a los datos de entrenamiento.
Los hiperparámetros son configuraciones externas al modelo que se establecen antes del proceso de entrenamiento de una red neuronal y que tienen un impacto significativo en el desempeño y la capacidad de generalización del modelo. A diferencia de los parámetros, que son aprendidos directamente a partir de los datos (como los pesos y los sesgos), los hiperparámetros deben ser definidos manualmente y ajustados a través de la experimentación.
|
Hiperparámetro |
Descripción |
|
Número de Capas (Number of Layers) |
Cantidad de capas ocultas en la red neuronal. |
|
Número de Neuronas (Number of Neurons) |
Cantidad de neuronas en cada capa de la red. |
|
Tasa de Aprendizaje (Learning Rate) |
Influencia de los pesos (%) en el aprendizaje. Valor de 0 a 1 (100%). |
|
Tamaño del Lote (Batch Size) |
Número de muestras que se utilizan en cada iteración de entrenamiento. |
|
Épocas (Epochs) |
Número total de veces que el conjunto de datos de entrenamiento es pasado a través de la red. |
|
Momento (Momentum) |
Técnica que ayuda a acelerar el proceso de optimización evitando mínimos locales. |
|
Función de Activación (Activation Function) |
Función que determina la salida de una neurona basada en su entrada (ej. ReLU, Sigmoide). |
A continuación, se muestra el trabajo realizado por el instituto privado de investigación INS de Genay-Lyon (Francia) [6], con quien colaboro. Este trabajo se centra en la caracterización de recubrimientos anodizados (MAO) en aleaciones de aluminio 2024 T3, prediciendo su resistencia a la corrosión (resistencia a la niebla salina) mediante un conjunto de datos (dataset) formado por datos electroquímicos obtenidos de la concatenación de ensayos ACET [7]/resistencia a la polarización (datos de entrada) y resistencia a la niebla salina neutra (datos de salida). Se ha utilizado una arquitectura de redes neuronales secuencial y completamente conectada (todas las neuronas conectan con todas) [5,3,2,2] con las siguientes capas y neuronas [capa de entrada con neuronas (5 datos de entrada), 2 capas ocultas de 3 y 2 neuronas respectivamente y una capa final de salida con 2 neuronas]. Aumentar el número de capas ocultas permite capturar relaciones más complejas y no lineales para obtener una mayor capacidad de modelado. El aprendizaje utilizado ha sido supervisado ya que todos los datos introducidos estaban etiquetados.

En el trabajo se utilizó una tasa de aprendizaje del 0,3 (30% de influencia de los pesos en el aprendizaje que permite una mayor estabilidad del modelo y el mismo no está tan sujeto a las variaciones por epoca) y un momentum de 0,9 que promueve un aprendizaje más suave considerando valores de pesos anteriores en el modelo. El error de aprendizaje se minimizó después de 100 épocas. Todo este conjunto de hiperparámetros han permitido alcanzar una precisión del 96% en las predicciones, además de un error estándar aceptable de 12%.
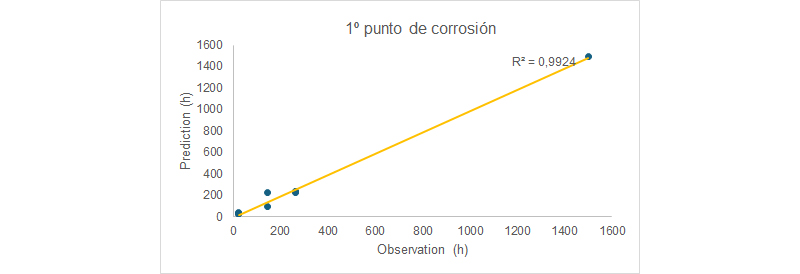
Como se puede apreciar en la imagen y, teniendo en cuenta las limitaciones del conjunto de datos que se poseía (no existen datos intermedios en el modelo) la correlación es aceptable.
La bondad del dataset es esencial para la generalidad del aprendizaje y, de hecho, es el factor más limitante a la hora de tener una buena predicción. En el campo de los recubrimientos no siempre es sencillo la recopilación de un conjunto de muestras representativo, diverso y amplio ya que los problemas específicos a los que nos enfrentamos muchas veces no generan ese tipo poblaciones ya sea porque dependen del cliente en muchos casos o porque el día a día nos hace pasar al siguiente problema sin poder detenernos a completar el dataset. La utilización de redes neuronales en el campo de los recubrimientos, como se demuestra en una amplio rango de ejemplos más cotidianos, tiene un gran potencial para optimizar y predecir las propiedades y el comportamiento de materiales recubiertos.

Bibliografía
[1] W. S. McCulloch and W. Pitts, "A logical calculus of the ideas immanent in nervous activity", Bull. Math. Biophys., vol. 5, no. 4, pp. 115133, 1943.
[2] F. Rosenblatt, "The perceptron: a probabilistic model for information storage and organization in the brain", Psychol. Rev., vol. 65, no. 6, pp. 386408, 1958.
[3] M. Minsky and S. Papert, Perceptrons: An Introduction to Computational Geometry, Cambridge, MA, USA: MIT Press, 1969.
[4] D. E. Rumelhart, G. E. Hinton, and R. J. Williams, "Learning representations by back-propagating errors", Nature, vol. 323, no. 6088, pp. 533536, 1986.
[5] A. Krizhevsky, I. Sutskever, and G. E. Hinton, "ImageNet classification with deep convolutional neural networks", in Advances in Neural Information Processing Systems (NIPS), 2012, pp. 10971105.
[6] A. Finke, J. Escobar, J. Munoz, and M. Petit, "Prediction of salt spray test results of micro arc oxidation coatings on AA2024 alloys by combination of accelerated electrochemical test and artificial neural network", Surf. Coat. Technol., vol. 421, p. 127370, 2021. INS, 450 rue Ampère, Z.I. Lyon nord - 69730 GENAY, France.
[7] J. J. Gracenea, "ACET as a tool for quality control of the aluminium coating", Int. Paint Coat. Mag., vol. 6, pp. 5661, 2012; J. J. Gracenea, M. J. Gimeno, and J. J. Suay, "The fast lane to failure. Cyclic impedance test gives rapid characterization of coating breakdown", Eur. Coat. J., no. 3, pp. 8486, 2011; J. Molina, M. Puig, M. J. Gimeno, R. Izquierdo, J. J. Gracenea, and J. J. Suay, "Influence of zinc molybdenum phosphate pigment on coatings performance studied by electrochemical methods", Prog. Org. Coat., vol. 97, pp. 244253, 2016.
La utilización de redes neuronales en el campo de los recubrimientos tiene un gran potencial para optimizar y predecir las propiedades y el comportamiento de materiales recubiertos










")


